The Best Infra for Serving Open-source Models
Serve any model on blazing-fast autoscaling infra with inference speeds 2-3x faster than vLLM and other solutions. Powered by LoRAX and Turbo LoRA.


Our Cloud or Yours

Predibase Cloud
Automatically spin up a private, serverless GPU deployment for any base model and serve 100s of fine-tuned models on top using LoRAX.

Virtual Private Cloud
Use your own cloud environment for complete control and the strictest privacy and security.
Learn more

At Convirza, our workload can be extremely variable, with spikes that require scaling up to double-digit A100 GPUs to maintain performance. The Predibase Inference Engine and LoRAX allow us to efficiently serve 60 adapters while consistently achieving an average response time of under two seconds. Predibase provides the reliability we need for these high-volume workloads. The thought of building and maintaining this infrastructure on our own is daunting—thankfully, with Predibase, we don’t have to.
Giuseppe Romagnuolo, VP of AI at Convirza
At Convirza, our workload can be extremely variable, with spikes that require scaling up to double-digit A100 GPUs to maintain performance. The Predibase Inference Engine and LoRAX allow us to efficiently serve 60 adapters while consistently achieving an average response time of under two seconds. Predibase provides the reliability we need for these high-volume workloads. The thought of building and maintaining this infrastructure on our own is daunting—thankfully, with Predibase, we don’t have to.
Giuseppe Romagnuolo, VP of AI at Convirza

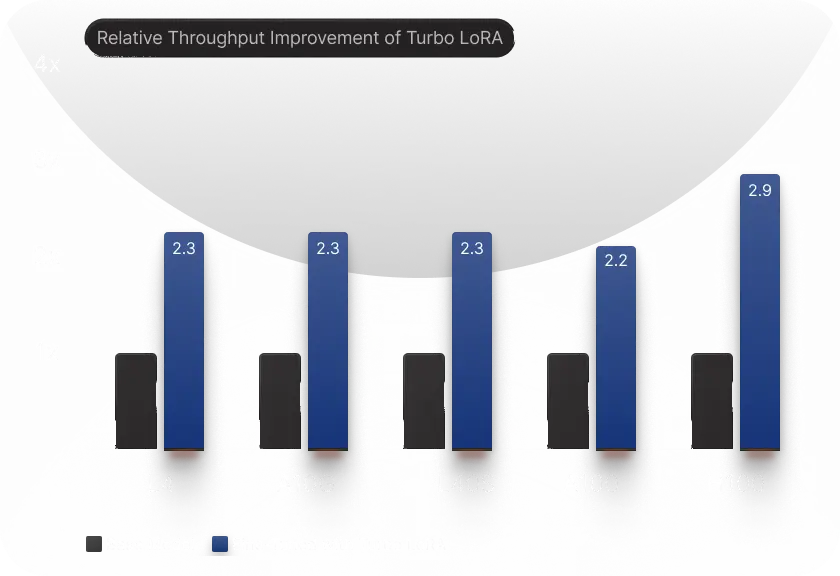
Unprecedented Speed And Efficiency For Small Language Models
2-3x faster with Turbo LoRA
Experience a 2-3x boost in throughput with Turbo LoRA, the industry’s fastest serving infrastructure for fine-tuned small language models.
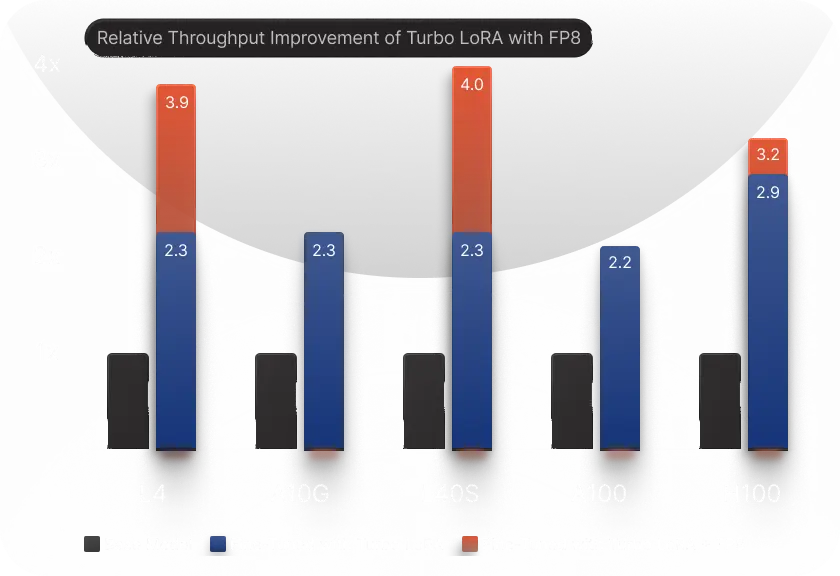
Accelerate Deployments With FP8
Leverage FP8 support to reduce inference time and costs, maximizing the efficiency of your small language models.
Many Fine-Tuned Models. One GPU
LoRAX lets you serve multiple fine-tuned adapters from a single GPU rather than spin up dedicated deployments for each use case. Run experiments and POCs with excess capacity, not dedicated GPUs.
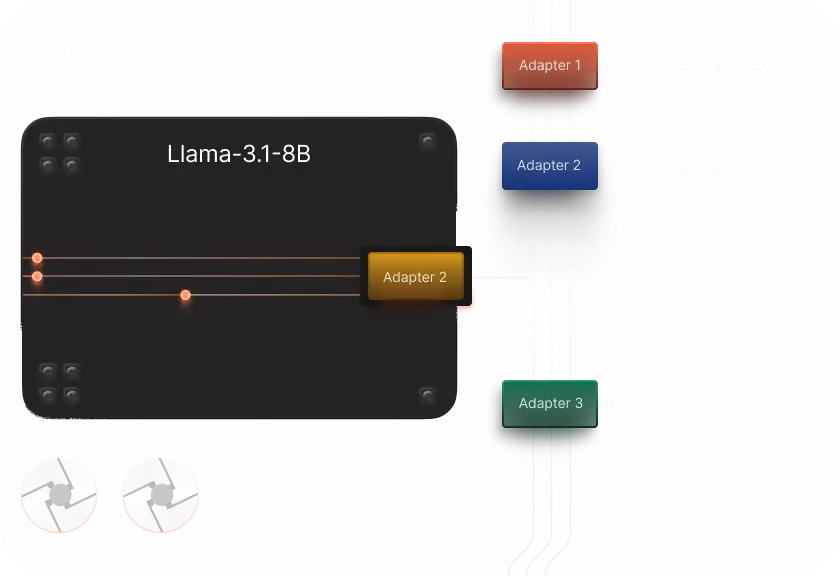
Fast, Efficient Deployments Powered
by LoRAX’s Innovations
Continuous Multi-Adapter Batching
Load multiple adapters on a single GPU deployment in a single model forward pass with nearly no impact on latency.
Tiered Weight Caching
Automatically unload unused adapters from GPU to CPU to disk to avoid out-of-memory errors.
Dynamic Adapter Loading
Each set of fine-tuned LoRA weights is loaded from storage just-in-time as requests come in at runtime, without blocking concurrent requests.
Serving is critical. Trust proven infrastructure.
Reserve GPU resources for critical loads
Enterprise customers can reserve guaranteed capacity from our A100 and H100 GPU fleet, ensuring you always have sufficient resources to serve your load.

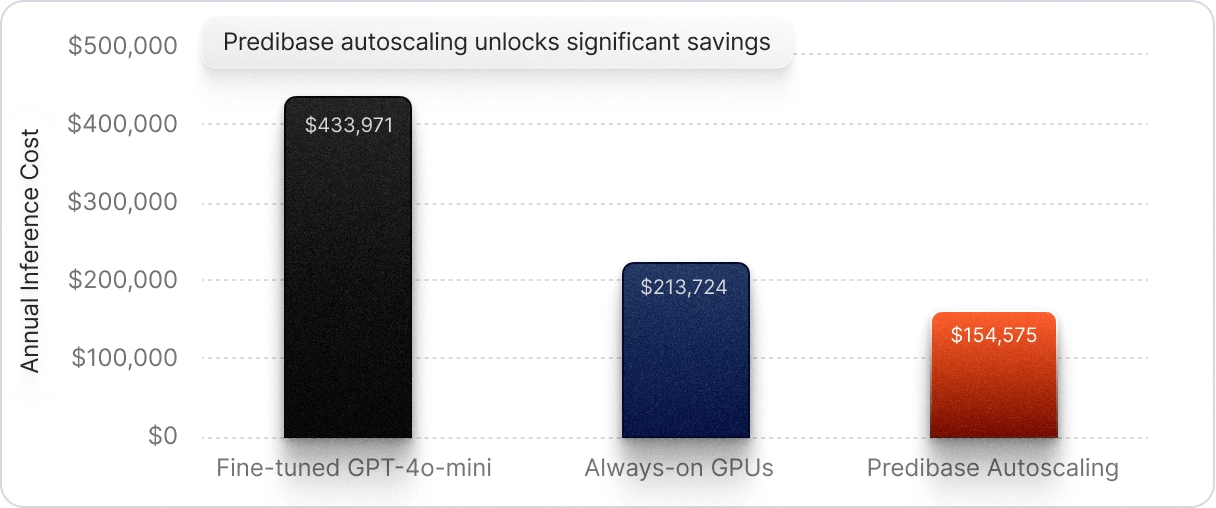
Cost-efficient auto-scaling
Automatically adjust GPU resources to precisely match your SLM demands, ensuring optimal performance and cost-efficiency at all times.
- 3 x H100 GPUs.
- 12 peak hours / day.
- Peak QPS: 50.
- Off-peak QPS: 5.
- Input: 1700 tokens.
- Output: 5 tokens.
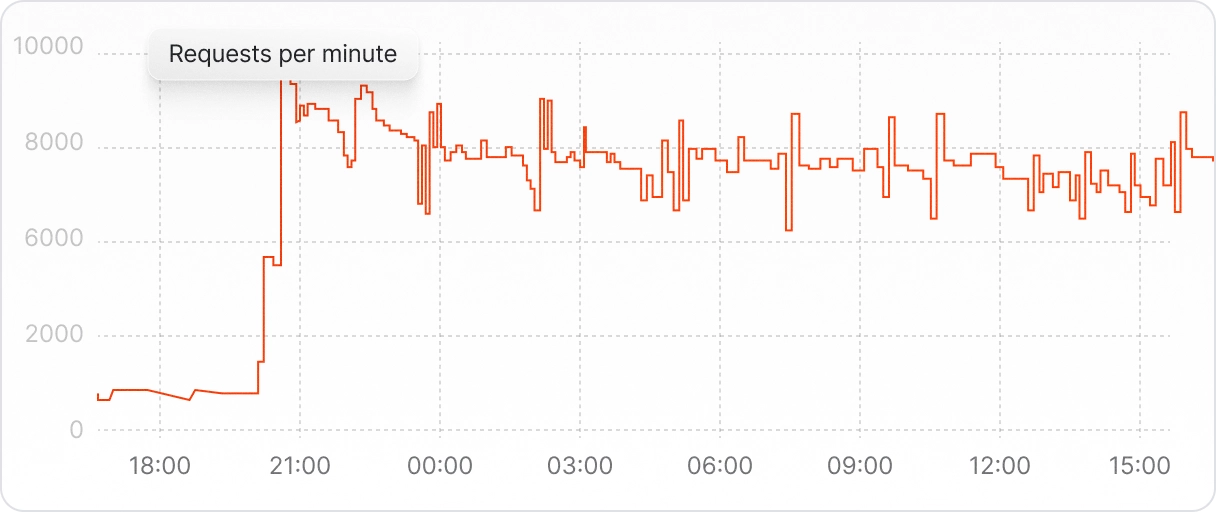
Built for Production Use-Cases
Scale to hundreds of requests per second without sacrificing throughput or reliability. Our infrastructure has served high-volume, mission critical loads without breaking a sweat.
Optimized Cold Starts
SaaS customers can ramp up additional GPUs for burst capacity in the blink of an eye. Guaranteed SLAs for enterprise customers.

Unmatched Control,
Scale, and Security
Deploy in Your Private Cloud
Safeguard your data with secure deployments within your virtual private cloud. Use your existing cloud spend commitments while benefiting from the power and performance of our software.

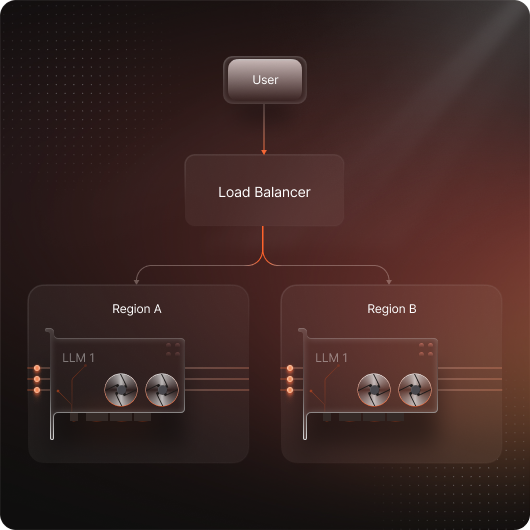
Multi-Region High Availability
Trust our multi-region architecture to minimize downtime and maintain seamless service for your small language models. In the event of a regional disruption, your multi-region deployments will reallocate local GPU resources to meet your load requirements in seconds.
Real-time Insights
Gain detailed observability metrics to monitor and optimize the performance of your SLMs in real-time, addressing issues before they impact your business.
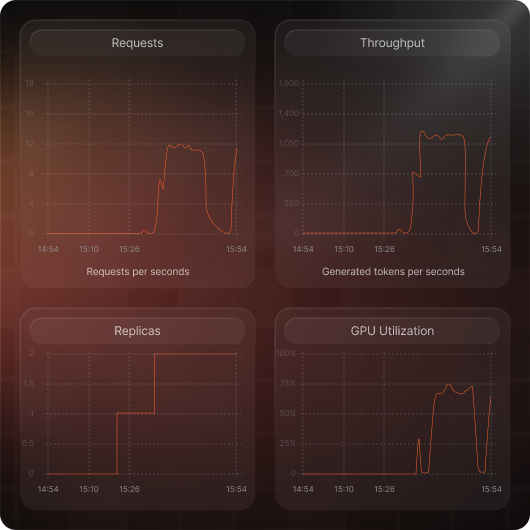
Built from the ground up for security

Manage Your Instance Through an Intuitive UI
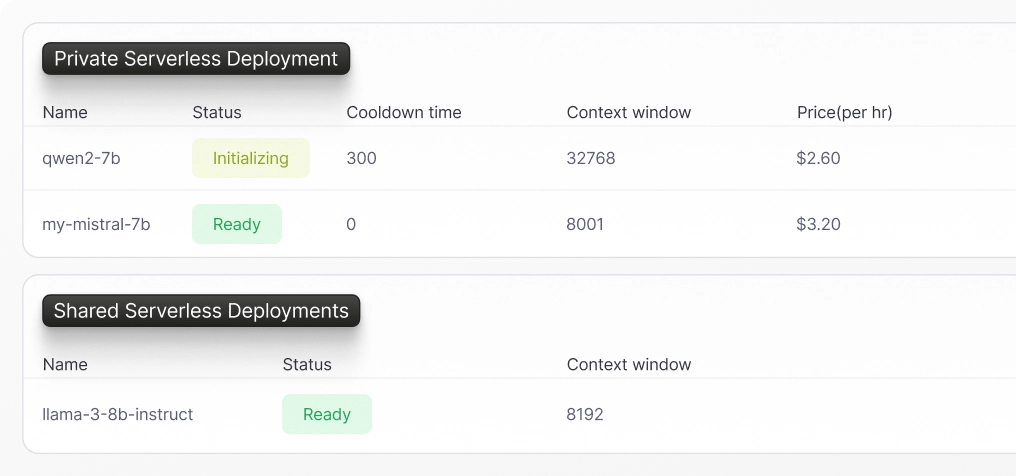
Manage Deployments in One Place
Get a bird’s eye view of your private serverless and shared serverless deployments. Create new deployments with just a few clicks or a few lines of code.
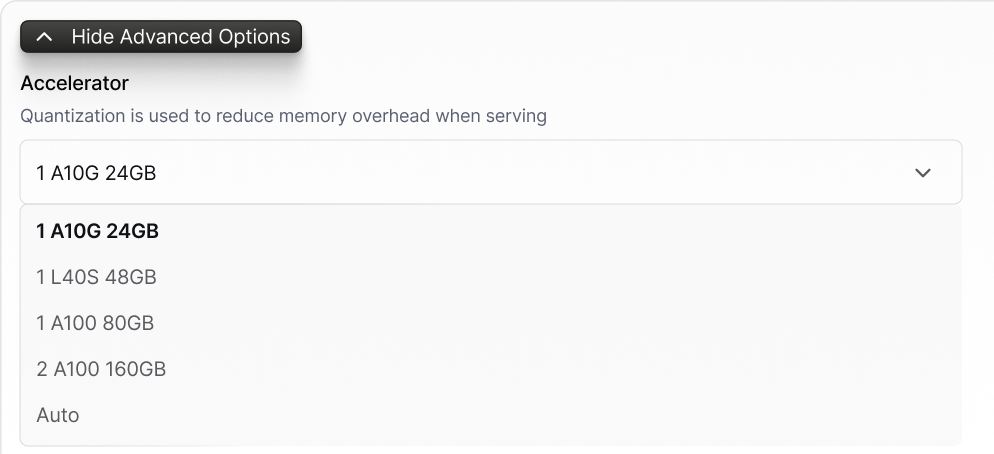
Choose your GPUs
Optimize for cost and performance by specifying a GPU for the deployment.
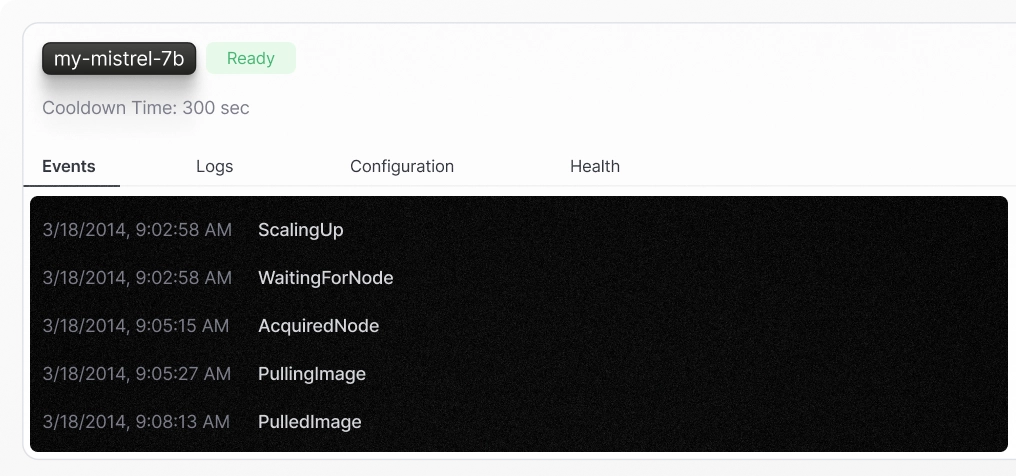
View a detailed event log
Dive into a full event log to diagnose errors
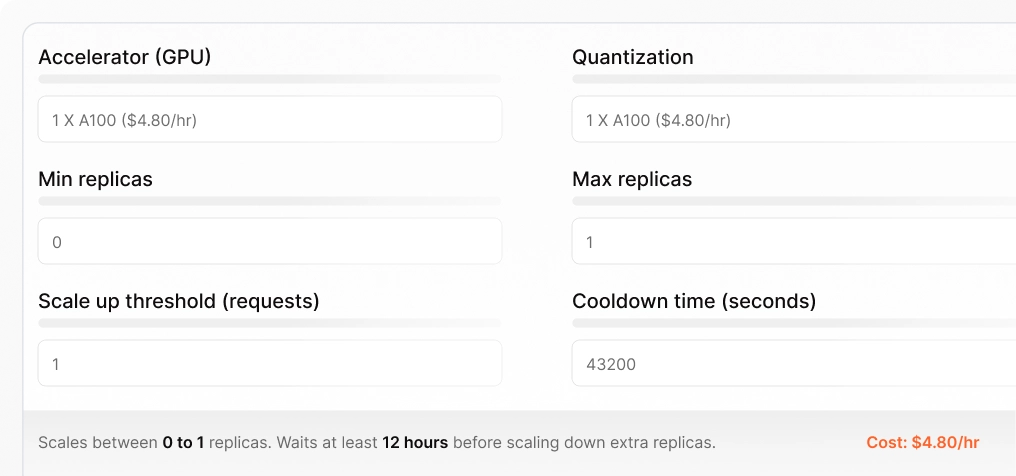
Fully Customizable Replica Settings
Our simple UI lets you easily configure the threshold for ramping up or spinning down additional GPU replicas. Also available via the SDK.