RFT in Action: The Future of AI Training
See how reinforcement fine-tuning and reward functions guide model training to maximize performance
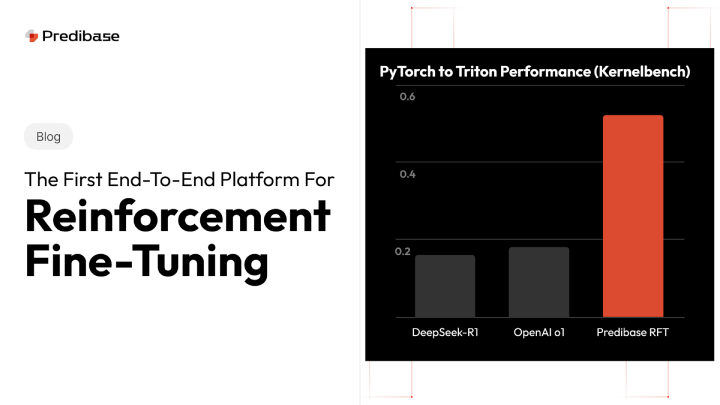
Translating PyTorch functions into efficient Triton GPU kernels is a complex but critical task for maximizing AI performance. While PyTorch makes it easy to write high-level code, it often struggles to fully leverage GPU hardware. Triton, on the other hand, enables highly optimized GPU execution—but writing Triton code requires deep expertise in GPU programming. Bridging this gap means automating the conversion process, turning high-level PyTorch functions into fast, efficient GPU kernels without manual effort. It’s a challenge that, if solved, can dramatically accelerate AI workloads and reduce development time.
For this particular model, we fine-tuned Qwen/Qwen2.5-Coder-32B-Instruct.
For this particular model, we fine-tuned Qwen/Qwen2.5-Coder-32B-Instruct.
Epoch
110100
Observations and Actions from the Predibase Team:
The model shows partial progress—generating code that may execute but is incorrect or inefficient. It also demonstrates tendencies toward reward hacking (like bypassing kernel work for easier wins) or making architectural mistakes that compromise performance or correctness.
Prompt
| Average Reward Score at Epoch 10 | ||||||
|---|---|---|---|---|---|---|
| PyTorch Function | formatting | compilation | correctness | speed | Total | |
| LeakyReLU | 0.910 | 0.890 | 0.760 | 0.000 | 2.560 | |
| Matmul for Lower Triangular Matrices | 0.920 | 0.880 | 0.930 | 0.000 | 2.730 | |
| Cosine Similarity Loss | 0.780 | 0.920 | 0.000 | 0.000 | 1.700 | |
Viewing prompt - LeakyReLU
<|im_start|>system
You are a helpful assistant that converts PyTorch code into Triton kernels.<|im_end|>
<|im_start|>user
Convert this PyTorch module implementationinto an equivalent Triton kernel:
<torch_code>
import torch
import torch.nn as nn
class Model(nn.Module):
"""
Simple model that performs a LeakyReLU activation.
"""
def __init__(self, negative_slope: float = 0.01):
"""
Initializes the LeakyReLU module.
Args:
negative_slope (float, optional): The negative slope of the activation function. Defaults to 0.01.
"""
super(Model, self).__init__()
self.negative_slope = negative_slope
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Applies LeakyReLU activation to the input tensor.
Args:
x (torch.Tensor): Input tensor of any shape.
Returns:
torch.Tensor: Output tensor with LeakyReLU applied, same shape as input.
"""
return torch.nn.functional.leaky_relu(x, negative_slope=self.negative_slope)
batch_size = 16
dim = 16384
def get_inputs():
x = torch.randn(batch_size, dim)
return [x]
def get_init_inputs():
return [] # No special initialization inputs needed
</torch_code>
The Triton kernel should:
1. Import torch, triton, and triton.language as tl and other necessary modules
2. Use @triton.jit decorator on the kernel implementation (not the entrypoint function)
3. Have proper grid and block sizes
4. Use a mask in the load/store operations
5. Use typed constants (tl.constexpr)
6. Handle tensor dimensions correctly
7. Return output matching PyTorch's implementation
8. Do not include any test code in your response, only the Triton kernel implementation and entrypoint function
The triton.language (tl) module supports the following methods: PropagateNan, TRITON_MAX_TENSOR_NUMEL, abs, advance, arange, argmax, argmin, associative_scan, atomic_add, atomic_and, atomic_cas, atomic_max, atomic_
min, atomic_or, atomic_xchg, atomic_xor, bfloat16, block_type, broadcast, broadcast_to, cast, cat, cdiv, ceil, clamp, const, const_pointer_type, constexpr, cos, cumprod, cumsum, debug_barrier, device_assert, device
*print, div*rn, dot, dtype, erf, exp, exp2, expand_dims, fdiv, flip, float16, float32, float64, float8e4b15, float8e4b8, float8e4nv, float8e5, float8e5b16, floor, fma, full, function_type, histogram, inline_asm_ele
mentwise, int1, int16, int32, int64, int8, interleave, join, load, log, log2, make_block_ptr, max, max_constancy, max_contiguous, maximum, min, minimum, multiple_of, num_programs, pair_uniform_to_normal, permute, p
hilox, pi32_t, pointer_type, program_id, rand, rand4x, randint, randint4x, randn, randn4x, range, ravel, reduce, reshape, rsqrt, sigmoid, sin, softmax, sort, split, sqrt, sqrt_rn, static_assert, static_print, stati
c_range, store, str_to_ty, sum, swizzle2d, tensor, trans, uint16, uint32, uint64, uint8, uint_to_uniform_float, umulhi, view, void, where, xor_sum, zeros, zeros_like
The entrypoint function must be named: fn_20_LeakyReLU_triton
The Triton kernel implementation (called by the entrypoint) must be named: fn_20_LeakyReLU_kernel
No computation logic should be done within the entrypoint function. All computation logic should be done within the Triton kernel implementation.
The final generated code in the response must start with <triton_code> and end with </triton_code> tags.<|im_end|>
<|im_start|>assistantReward Graphs
Completion and Reward Scores
Completion at Epoch 10 - LeakyReLU
total: 3.000formatting: 1.000compilation: 1.000correctness: 1.000speed: 0.000
Observation
By epoch 10, the model is able to generate a correct kernel, but it is slower than the original PyTorch implementation.
import torch
import triton
import triton.language as tl
@triton.jit
def fn_20_LeakyReLU_kernel(
x_ptr, # *Pointer to input tensor
y_ptr, # *Pointer to output tensor
N, # Total number of elements in the input tensor
negative_slope, # Negative slope for the LeakyReLU
BLOCK_SIZE: tl.constexpr
):
# Calculate the index of the current thread
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < N
# Load input from global memory
x = tl.load(x_ptr + offsets, mask=mask, other=0.0)
# Apply LeakyReLU activation
y = tl.where(x >= 0, x, x * negative_slope)
# Write output to global memory
tl.store(y_ptr + offsets, y, mask=mask)
def fn_20_LeakyReLU_triton(x, negative_slope=0.01):
N = x.numel()
y = torch.empty_like(x)
# Define the grid and block size
BLOCK_SIZE = 1024
grid = lambda meta: (triton.cdiv(N, meta['BLOCK_SIZE']),)
# Launch the kernel
fn_20_LeakyReLU_kernel[grid](x, y, N, negative_slope, BLOCK_SIZE=BLOCK_SIZE)
return y